
Hey, there Firebase developers. Did you hear the exciting news? Last month at Google I/O, we announced support for collection group queries in Cloud Firestore! Let’s dig into this new feature a little more, and see if we answer some of your burning questions…
Q&A
Q: So, what are collection group queries and why should I care?
In Cloud Firestore, your data is divided up into documents and collections. Documents often point to subcollections that contain other documents, like in this example, where each restaurant document contains a subcollection with all the reviews of that restaurant.
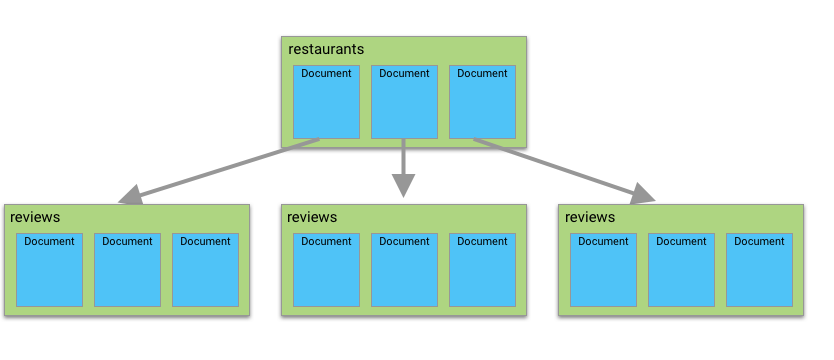
In the past, you could query for documents within a single collection. But querying for documents across multiple collections wasn’t possible. So, for instance, I could search for all reviews for Tony’s Tacos, sorted by score, because those are in a single subcollection.
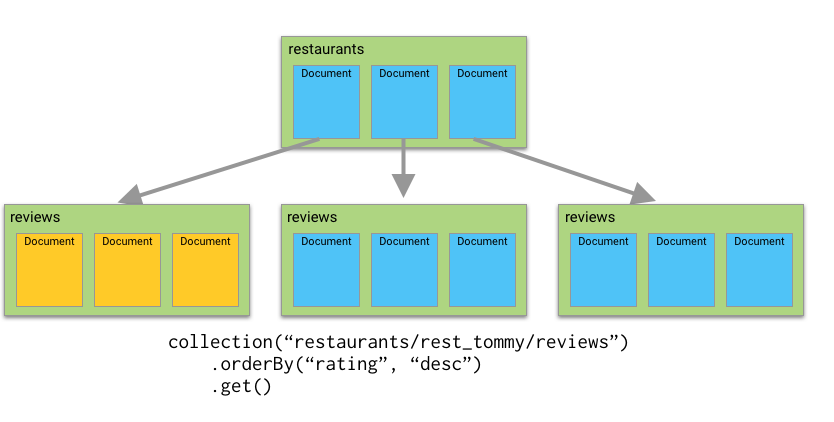 ]
But if I wanted to find reviews for all restaurants where I was the author, that wasn’t possible before because that query would span multiple
]
But if I wanted to find reviews for all restaurants where I was the author, that wasn’t possible before because that query would span multiple reviews collections.
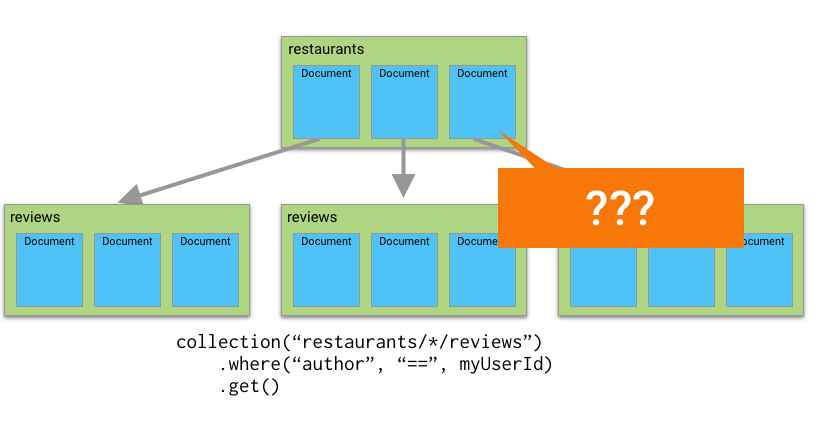
But with collection group queries, you’re now able to query for documents across a collection group; that is, several collections that all have the same name. So I can now search for all the reviews I’ve written, even if they’re in different collections.
Q: Great! So how do I use them?
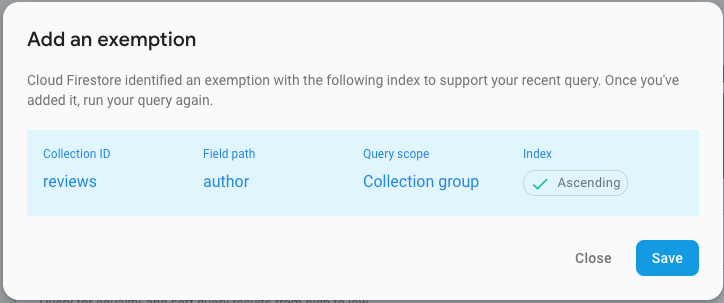
The most important step in using a collection group query is enabling the index that allows you to run a query in the first place. Continuing our example, if we want to find all reviews that a particular person has written, we would tell Cloud Firestore, “Go index every author field in every single reviews collection as if it were one giant collection.”
You can do this manually by going to the Firebase Console, selecting the “Index” tab for Cloud Firestore, going to the “Single Field” section, clicking the “Add exemption” button, specifying you want to create an exemption for the “reviews” collection with the “author” field and a “collection group” scope, and then enabling ascending and/or descending indexes.  ](https://3.bp.blogspot.com/-i1L5Qc-C0Fo/XQqmTUQvhRI/AAAAAAAADoc/_6asA5NtaxsOj76dBx9-rctGNajPFBvfACLcBGAs/s1600/4.png)
](https://3.bp.blogspot.com/-i1L5Qc-C0Fo/XQqmTUQvhRI/AAAAAAAADoc/_6asA5NtaxsOj76dBx9-rctGNajPFBvfACLcBGAs/s1600/4.png)
But that’s a lot of steps, and I tend to be pretty lazy. So, instead, I like enabling collection group indexes the same way I enable composite indexes. First, I’ll write the code for the collection group query I want to use and attempt to run it. For example, here’s some sample code I might write to search for all reviews where I’m the author.
const myUserId = firebase.auth().currentUser.uid;
const myReviews = firebase.firestore().collectionGroup('reviews');
.where('author', '==', myUserId);
myReviews.get().then(function (querySnapshot) {
// Do something with these reviews!
});Notice that I’m specifying a collectionGroup() for my query instead of a collection or document.
When I run this code, the client SDK will give me an error message, because the collection group index hasn’t been created yet. But along with this error message is a URL I can follow to fix it.

Following that URL will take me directly to the console, with my collection group index ready to be created.
Once that index has been created, I can go ahead and re-run my query, and it will find all reviews where I’m the author.
If I wanted to search by another field (like rating), I would need to create a separate index with the rating field path instead of the author field.
Q: Any gotchas I need to watch out for?
Why, yes! There are three things you should watch out for.
First, remember that collection group queries search across all collections with the same name (e.g., reviews), no matter where they appear in my database. If, for instance, I decided to expand into the food delivery service and let users write reviews for my couriers, then suddenly my collection group query would return reviews both for restaurants and for couriers in the same query.
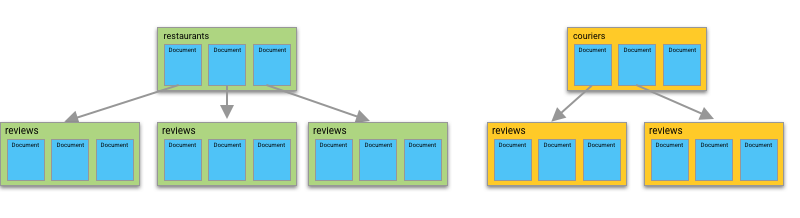
This is (probably) not what I want, so the best thing to do would be to make sure that collections have different names if they contain different objects. For example, I would probably want to rename my courier review collections something like courier_reviews.
If it’s too late to do that, the second best thing would be to add something like an isCourier Boolean field to each document and then limit your queries based on that.
Second, you need to set up special security rules to support queries. You might think in my example that if I had a security rule like this:
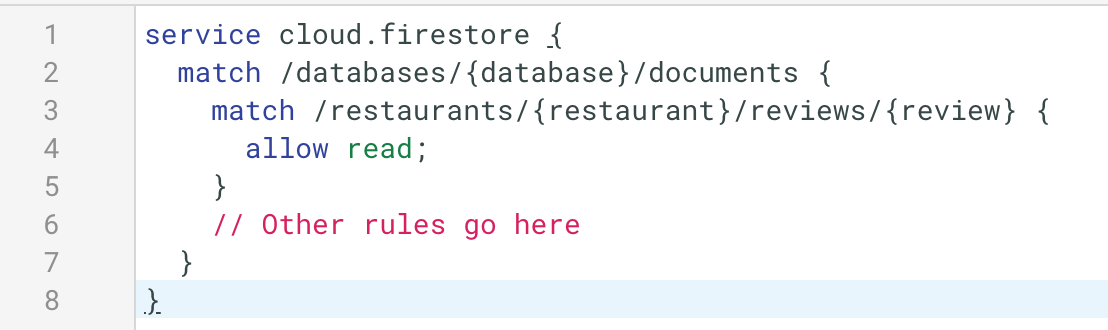
I would be able to run this collection group query. After all, all of my review documents would fall under this rule, right? So why does this fail?
Well if you’ve seen our video on Cloud Firestore security rules, you would know that when it comes to querying multiple documents, Cloud Firestore needs to prove that a query would be allowed by the security rules without actually examining the underlying data in your database.
And the issue with my collection group query is that there’s no guarantee it will only return documents in the restaurants → reviews collection. Remember, I could just as easily have a couriers → reviews collection, or a restaurant → dishes → reviews collection. Cloud Firestore has no way of knowing unless it examines the results of the data set.
So the better way to do this is to declare that any path that ends with “reviews” can be readable based on whatever security rules I want to implement. Something like this:
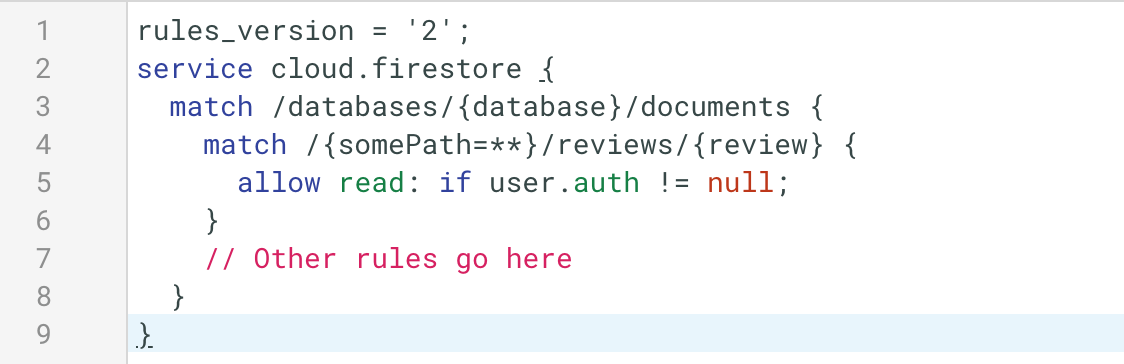
Note that this solution requires using version 2 of the security rules, which changes the way recursive wildcards work.
Third, keep in mind that these collection group indexes are counted against the 200 index exemptions limit per database. So before you start creating collection group indexes willy-nilly, take a moment and ask yourself what queries you really want to run, and just create indexes for those. You can always add more later.
Q: Can I do collection group queries for multiple fields?
Yes. If you’re doing equality searches across multiple fields, just make sure you have an index created for each field with a collection group scope.
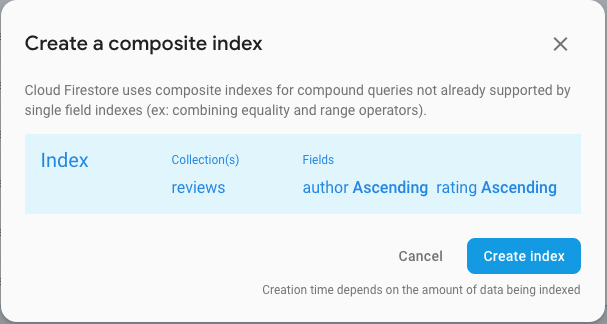
If you’re combining an equality clause with a greater-than-or-less-than clause, you’ll need to create a composite index with a collection group scope. Again, I find it’s best to just try to run the query in the code and follow the link to generate the index. For instance, trying to run a collection group query for all reviews that I wrote with a rating of 4 or higher gave me a URL that opened this dialog box.
Q: It still seems like I could do all of this in a top-level collection. How are collection group queries better?
So this question is based on the idea that one alternative to creating collection group queries is to not store data hierarchically at all, and just store documents in a separate top level collection.
For instance, I could simply keep my restaurants and my reviews as two different top-level collections, instead of storing them hierarchically.
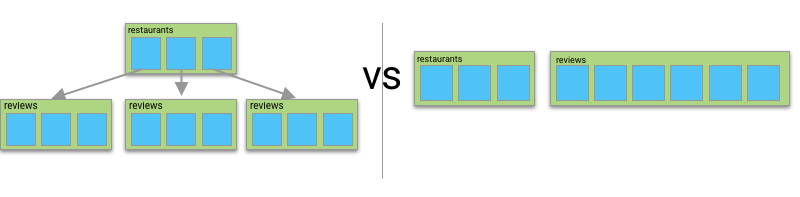
With this setup, I can still search for all reviews belonging to a particular restaurant…
 ](https://3.bp.blogspot.com/-muaAg5LVkgw/XQqshwT6OyI/AAAAAAAADqM/Axcfy61jDg4R120Vlb-dk7ciFAQJAwh6gCLcBGAs/s1600/12.png)
](https://3.bp.blogspot.com/-muaAg5LVkgw/XQqshwT6OyI/AAAAAAAADqM/Axcfy61jDg4R120Vlb-dk7ciFAQJAwh6gCLcBGAs/s1600/12.png)
As well as all reviews belonging to a particular author…
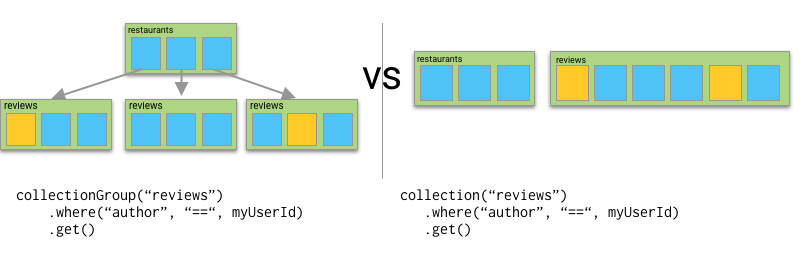
And you’ll notice that with the separate top level collection, I no longer need to use one of my 200 custom indexes to create this query.
So, why go with the subcollection setup? Are collection group queries needed at all? Well, one big advantage to putting documents into subcollections is that if I expect that I’ll want to order restaurant reviews by rating, or publish date, or most upvotes, I can do that within a reviews subcollection without needing a composite index. In the larger top level collection, I’d need to create a separate composite index for each one of those, and I also have a limit of 200 composite indexes.
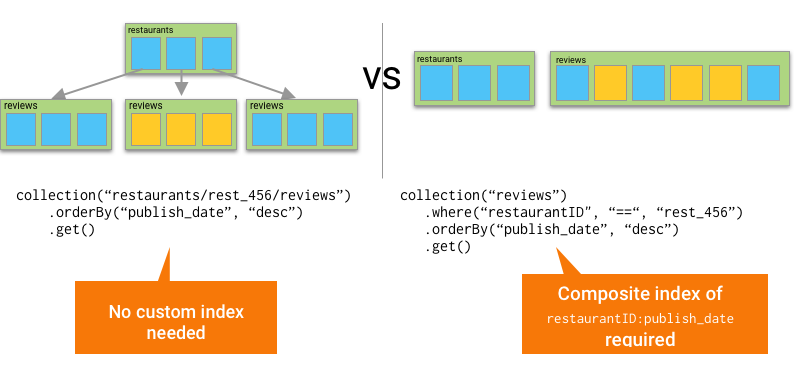
Also, from a security rules standpoint, it’s fairly common to restrict child documents based on some data that exists in their parent, and that’s significantly easier to do when you have data set up in subcollections.
So when should you store things in a separate top level collection vs. using subcollections? If you think you have a situation where you’re mostly going to be querying documents based on a common “parent” and only occasionally want to perform queries across all collections, go with a subcollection setup and enable collection group queries when appropriate. On the other hand, if it seems like no matter how you divide up your documents, the majority of your queries are going to require a collection group query, maybe keep them as a top level collection.
But if that’s too hard to figure out, I would say that you should pick the solution that makes sense to you intuitively when you first think about your data. That tends to be the correct answer most of the time.
Any questions?
Hope that helps you get more comfortable with collection group queries! As always, if you have questions, feel free to check out our documentation, or post questions on Stack Overflow.