
This article originally appeared in the Firebase Developer Community blog.
We like saying lots of impressive things about Cloud Firestore’s performance – “performance scales with the size of the result set, not the underlying data set”, and that “it’s virtually impossible to create a slow query.” And, for the most part, this is true. You can query a data set with billions upon billions of records in it, and get back results faster than your user can move their thumb away from the screen.
But with that said, we occasionally hear from developers that Cloud Firestore feels slow in certain situations, and it takes longer than expected to get results back from a query. So why is that? Let’s take a look at some of the most common reasons that Cloud Firestore might seem slow, and what you can do to fix them.
1. It’s the data, silly!
Probably the most common explanation for a seemingly slow query is that your query is, in fact, running very fast. But after the query is complete, we still need to transfer all of that data to your device, and that’s the part that’s running slowly.
So, yes, you can go ahead and run a query of all sales people in your organization, and that query will run very fast. But if that result set consists of 2000 employee documents and each document includes 75k of data, you have to wait for your device to download 150MB of data before you can see any results.
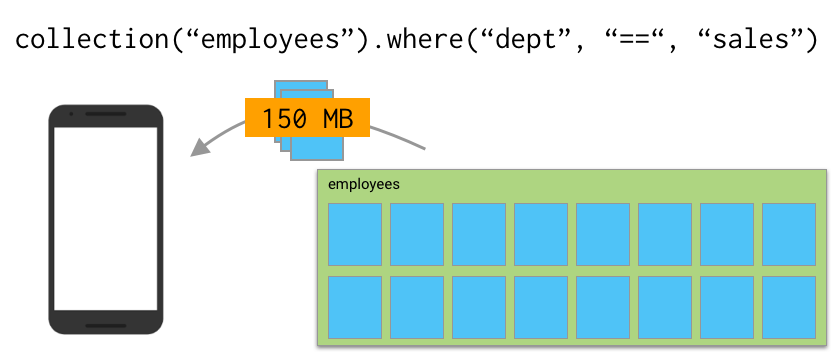
How to make this faster
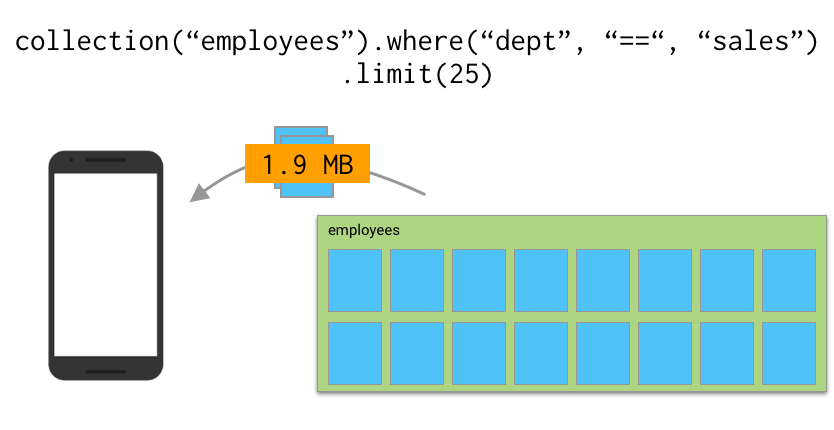
The best way to fix this issue is to make sure you’re not transferring down more data than you need. One simple option is to add limits to your queries. If you suspect that your user only needs the first handful of results from your employee list, add a limit(25) to the end of your query to download just the first batch of data, and then only download further records if your user requests them. And, hey, it just so happens I have an entire video all about this!
If you really think it’s necessary to query and retrieve all 2000 sales employees at once, another option is to break those records up into the documents that contain only the data you’ll need in the initial query, and then put any extra details into a separate collection or subcollection. Those other documents won’t get transferred on that first fetch, but you can request them later as your user needs them.
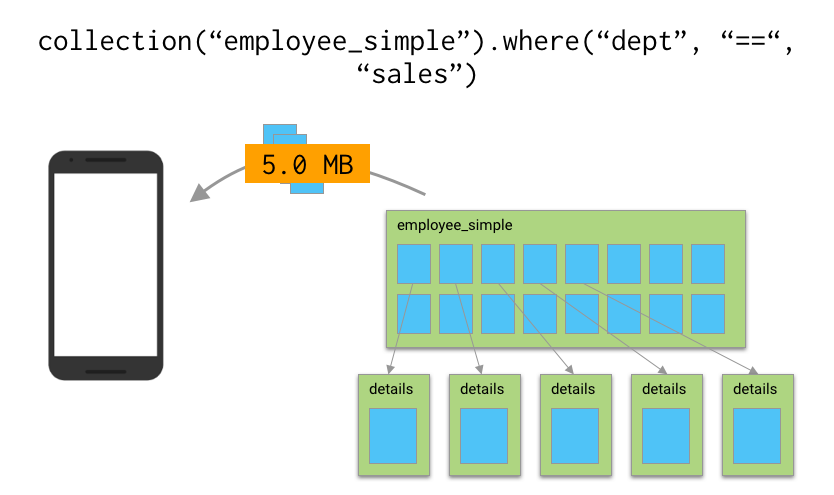
Having smaller documents is also nice in that, if you have a realtime listener set up on a query and a document is updated, the changed document gets sent over to your device. So by keeping your documents smaller, you’ll also have less data transferred every time a change happens in your listeners.
2. Your offline cache is too big
So Cloud Firestore’s offline cache is pretty great. With persistence enabled, your application “just works”, even if your user goes into a tunnel, or takes a 9-hour plane flight. Documents read while online will be available offline, and writes are queued up locally until the app is back online. Additionally, your client SDK can make use of this offline cache to avoid downloading too much data, and it can make actions like document writes feel faster. However Cloud Firestore was not designed as an “offline first” database, and as such, it’s currently not optimized for handling large amounts of data locally.
So while Cloud Firestore in the cloud indexes every field in every document in every collection, it doesn’t (currently) build any of those indexes for your offline cache. This means that when you query documents in your offline cache, Cloud Firestore needs to unpack every document stored locally for the collection being queried and compare it against your query.
Or to put it another way, queries on the backend scale with the size of your result set, but locally, they kinda scale with the size of the data in the collection you’re querying.
Now, how slow local querying ends up being in practice depends on your situation. I mean, we’re still talking about local, non-network operations here, so this can (and often is) faster than making a network call. But if you have a lot of data in one single collection to sort through, or you’re just running on a slow device, local operations on a large offline cache can be noticeably slower.
How to make this better
First, follow the best practices mentioned in the previous section: add limits to your queries so you’re only retrieving the data that you think your users will need, and consider moving unneeded details into subcollections. Also, if you followed the “several subcollections vs a separate top level collection” discussion at the end of my earlier post, this would be a good argument for the “several subcollections” structure, because the cache only needs to search through the data in these smaller collections.
Second, don’t stuff more data in the cache than you need. I’ve seen some cases where developers will do this intentionally by querying a massive number of documents when their application first starts up, then forcing all future database requests to go through the local cache, usually in a scheme to reduce database costs, or make future calls faster. But in practice, this tends to do more harm than good.
Third, consider reducing the size of your offline cache. The size of your cache is set to 100MB on mobile devices by default, but in some situations, this might be too much data for your device to handle, particularly if you end up having most of your data in one massive collection. You can change this size by modifying the cacheSizeBytes value in your Firebase settings, and that’s something you might want to do for certain clients.
Fourth, try disabling persistence entirely and see what happens. I generally don’t recommend this approach – as I mentioned earlier, the offline cache is pretty great. But if a query seems slow and you don’t know why, re-running your app with persistence turned off can give you a good idea if your cache is contributing to the problem.
3. Your zig-zag merge join is zigging when it should zag
So zig-zag merge joins, in addition to being my favorite algorithm name ever, are very convenient in that they allow you to coalesce results from different indexes together without having to rely on a composite index. They essentially do this by jumping back and forth between two (or more) indexes sorted by document ID and finding matches between them.
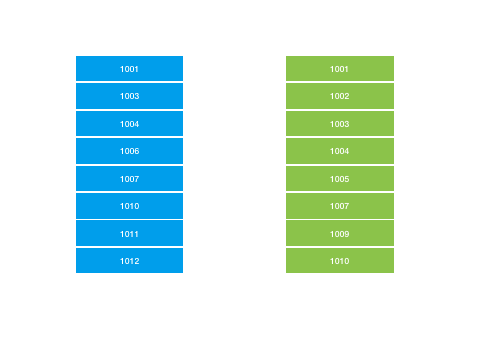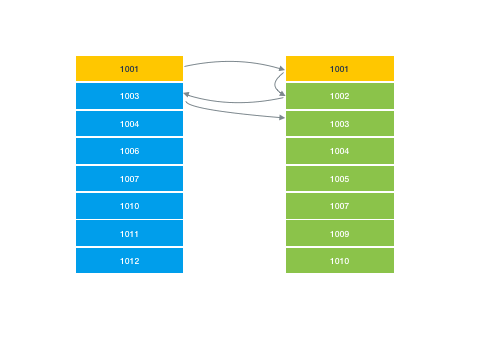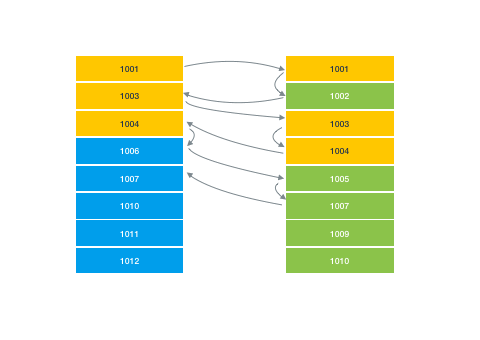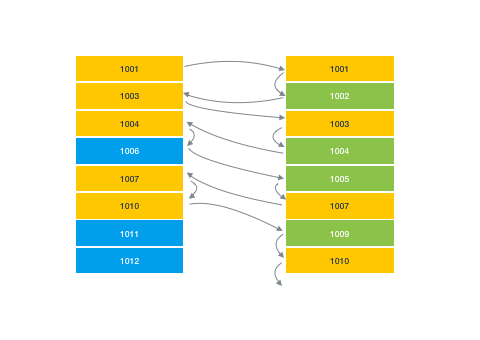
But one quirk about zig-zag merge joins is that you can run into performance issues where both sets of results are quite large, but the overlap between them is small. For example, imagine a query where you were looking for expensive restaurants that also offered counter service.
restaurants.where('price', '==', '$$$$').where('orderAtCounter', '==', 'true')While both of these groups might be fairly large, there’s probably very little overlap between them. Our merge join would have to do a lot of searching to give you the results you want.
So if you notice that most of your queries seem fast, but specific queries are slow when you’re performing them against multiple fields at once, you might be running into this situation.
How to make this better
If you find that a query across multiple fields seems slow, you can make it performant by manually creating a composite index against the fields in these queries. The backend will then use this composite index in all future queries instead of relying on a zig zag merge join, meaning that once again this query will scale to the size of the result set.
4. You’re used to the Realtime Database
While Cloud Firestore has more advanced querying capabilities, better reliability, and scales better than the Firebase Realtime Database, the Realtime Database generally has lower latency if you’re in North America. It’s usually not by much, and in something like a chat app, I doubt you would notice the difference. But if you have an app that’s reliant upon very fast database responses (something like a real-time drawing app, or maybe a multiplayer game), you might notice that the Realtime Database feels… uhh… realtime-ier.
How to make this better
If your project is such that you need the lower latency that the Realtime Database provides (and you’re anticipating that most of your customers are in North America), and you don’t need some of the features that Cloud Firestore provides, feel free to use the Realtime Database for those parts of your project! Before you do, I would recommend reviewing this earlier blog post, or the official documentation, to make sure you understand the full set of tradeoffs between the two.
5. The laws of physics are keeping you down
Remember that even in the most perfect situation, if your Cloud Firestore instance is hosted in Oklahoma, and your customer is in New Delhi, you’re going to have at least 80 milliseconds of latency because of that whole “speed of light” thing. And, realistically, you’re probably looking at something more along the lines of a 242 millisecond round trip time for any network call. So, no matter how fast Cloud Firestore is to respond, you still need time for that response to travel between Cloud Firestore and your device.
How to make this better
First, I’d recommend using realtime listeners instead of one-time fetches. This is because using realtime listeners within the client SDKs gives you a lot of really nice latency compensation features. For instance, Cloud Firestore will present your listener with cached data while it’s waiting for the network call to return, giving you the ability to show results to your user faster. And database writes are applied to your local cache immediately, which means that you will see these changes reflected nearly instantly while your device is waiting for the server to confirm them.
Second, try to host your data where the majority of your customers are going to be. You have the option of selecting your Cloud Firestore location when you first initialize your database instance, so take a moment to consider what location makes the most sense for your app, not just from a cost perspective, but a performance perspective as well.
Third, consider implementing a reliable and cheap global communication network based on quantum entanglement, allowing you to circumvent the speed of light. Once you’ve done that, you probably can retire off of the licensing fees and forget about whatever app you were building in the first place.
Big exciting conclusion goes here!
So the next time you run into a Cloud Firestore query that seems slow, take a look through this list and see if you might be hitting one of these scenarios. While you’re at it, don’t forget that the best way to see how well your app is performing is to measure its performance out in the wild in real-life conditions, and Firebase Performance Monitoring is a great way of doing that. Consider adding Performance Monitoring to your app, and setting up a custom trace or two so you can see how your queries perform in the wild.