At Google I/O, we unveiled Firebase Data Connect, an all-new product bringing the power of PostgreSQL and relational querying to the Firebase ecosystem for the first time. With it, we’re introducing Query-Defined Infrastructure, a new paradigm for web/mobile app development that combines the iteration velocity of backend-as-a-service with the flexibility and security of custom server code.
Our existing database products, Realtime Database and Firestore, make the entire database accessible on the internet. These databases have configurable server-side Security Rules to allow certain types of data access to untrusted client applications, and provide administrative access through Cloud Functions. Data Connect works differently.
Data Connect lets you declare your application’s data model and the exact queries needed by your application. Using your data model, we automatically create a PostgreSQL database schema to fit your data model, secure server endpoints that talk to the database, and typesafe SDKs for your client application that talk to the server endpoints.
Using your data model, we automatically create a PostgreSQL database schema to fit your data model, secure server endpoints that talk to the database, and typesafe SDKs for your client application that talk to the server endpoints.
It’s like a “self-driving app server” made-to-order for your specific application. This blog post series will dive deep into the “how” and “why” of Data Connect, drawing on more than a decade of lessons learned from operating Firebase for millions of developers. If you just want to jump in developing with Data Connect, go sign up for preview access!
Three-Tier Application Architecture
A traditional “three-tier” application consists of a presentation tier that provides a user interface, an application tier that implements business logic, and a data tier that persists and retrieves information needed by the application.
The tiers are separated for good reason. The presentation tier is often running on an untrusted user device and so can’t directly implement business logic. The data tier often has needs that evolve independently of the needs of a single application. The application tier serves as a bridge between the user interface and the underlying data stores that power the experience.
But building that bridge is often full of redundancies. Many times, perhaps even most times, an application tier endpoint will implement very predictable logic. For example (pseudo-JS):
function listMyInvoices(params, context) {
checkAuthentication(params, context);
checkAuthorization(params, context);
let rawData = fetchSql("
SELECT
o.id as invoice_id, o.created_at as created_at, ii.quantity as quantity,
p.id as product_id, p.name as product_name, p.price as product_price
FROM orders o
INNER JOIN invoice_items ii ON ii.order_id = o.id
INNER JOIN products p ON ii.product_id = p.id
WHERE o.user_id = ? AND description LIKE ?
ORDER BY o.created_at DESC
LIMIT 20
", context.auth.uid, "%" + params.search + "%");
return formatData(rawData);
}
While every step performed within the endpoint is important and necessary, it’s also all boilerplate. There’s no particular special sauce here other than the structure of the query to the data tier (in this case a SQL database). Worse, this only covers the application tier. To fully develop this endpoint, I’ll need to define an API request and response structure in both presentation and application tiers as well as underlying data storage structure in both application and data tiers.
Is there any way we might streamline our application’s architecture to reduce boilerplate and redundant implementation?
A Tale of Two Tiers
“A ha!” we might say as we roll up our sleeves to simplify, “the problem is that we’re building three tiers when we really only need two!” But we’ve already established that the roles of the presentation, application, and data tiers are distinct and important. We’ll still need to get all those jobs done, we’ll just have to figure out a way to combine things a bit. The application tier, which sits between the other two, will need to “merge” into one of the others.
This isn’t a thought experiment! If you’ve ever used a Backend-as-a-Service or built an app using SSR Metaframeworks, you’ve used a “two-tier” pattern:
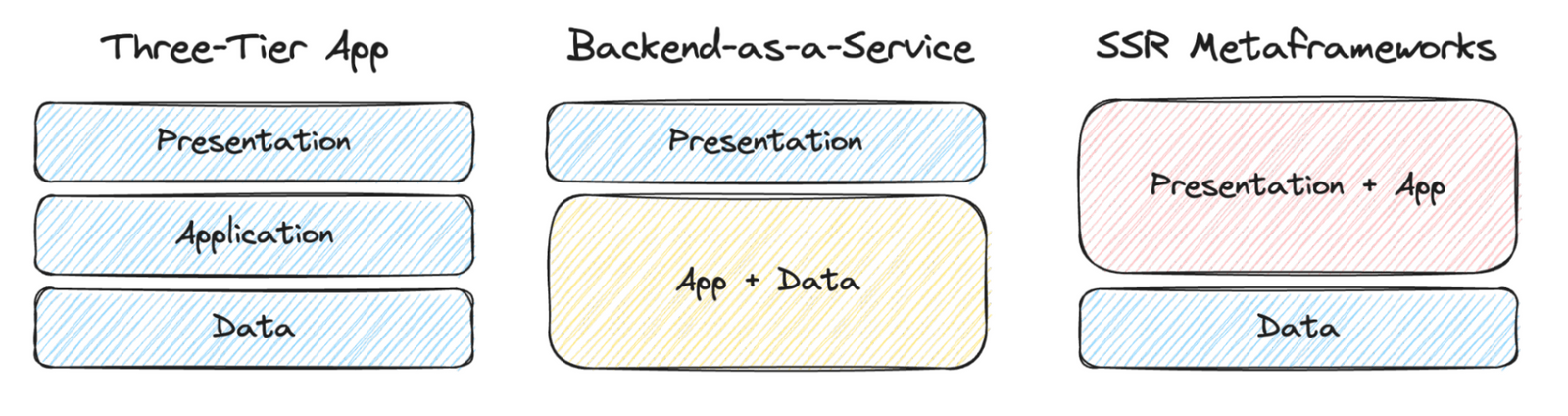
Backend-as-a-Service - P+AD Applications
Combining the application tier and the data tier makes it possible to build applications primarily using a frontend/mobile developer skillset. Typically, the developer builds a client application that directly connects to a managed “backend” to perform application activities. This can radically accelerate development, especially in the early stages of an application.
Traditional BaaS has a lot going for it, and we at Firebase are perhaps the best-known purveyors of such a service! There are, however, some tradeoffs to combining application and data tiers:
- Authorization can be difficult to reason about, especially when an untrusted client is capable of performing arbitrary operations against the data tier.
- Business logic is usually implemented in client code, which means building a client for a new platform is a more significant undertaking than a traditional three-tier app.
- Changes to the application’s data model can be particularly difficult to execute cleanly since there is no abstraction sitting between client and data.
Server-side Web Metaframeworks - PA+D Applications
Combining the presentation tier and the application tier makes it possible to build applications that define trusted server-side logic and untrusted client-side logic in a single codebase. This approach is largely enabled by JavaScript “metaframeworks” such as Next.js, Angular SSR, Nuxt, or SvelteKit.
Metaframeworks are growing rapidly in popularity for web development, replacing the client-focused “Single-Page Application” for many newer apps. As with BaaS, however, there are tradeoffs to the metaframework approach:
- Metaframeworks only provide an “all-in-one” solution for web development. If another client is needed (e.g. a mobile app), a separate API-based application tier must be built.
- Abstractions that hide the complexity of sharing code between trusted and untrusted environments can lead to security issues if not managed carefully.
- As a metaframework application grows in complexity it will often organically develop an independent application tier, entailing a complex migration.
A New Approach
What if we could combine the rapid cross-platform “all-in-one codebase” developer experience of a Backend-as-a-Service with the security and flexibility of a separate application tier? What if an application’s data model, authorization policy, and client libraries could all be driven by a single declarative source? We call this approach query-defined infrastructure (QDI), and it’s at the center of our new product, Firebase Data Connect.
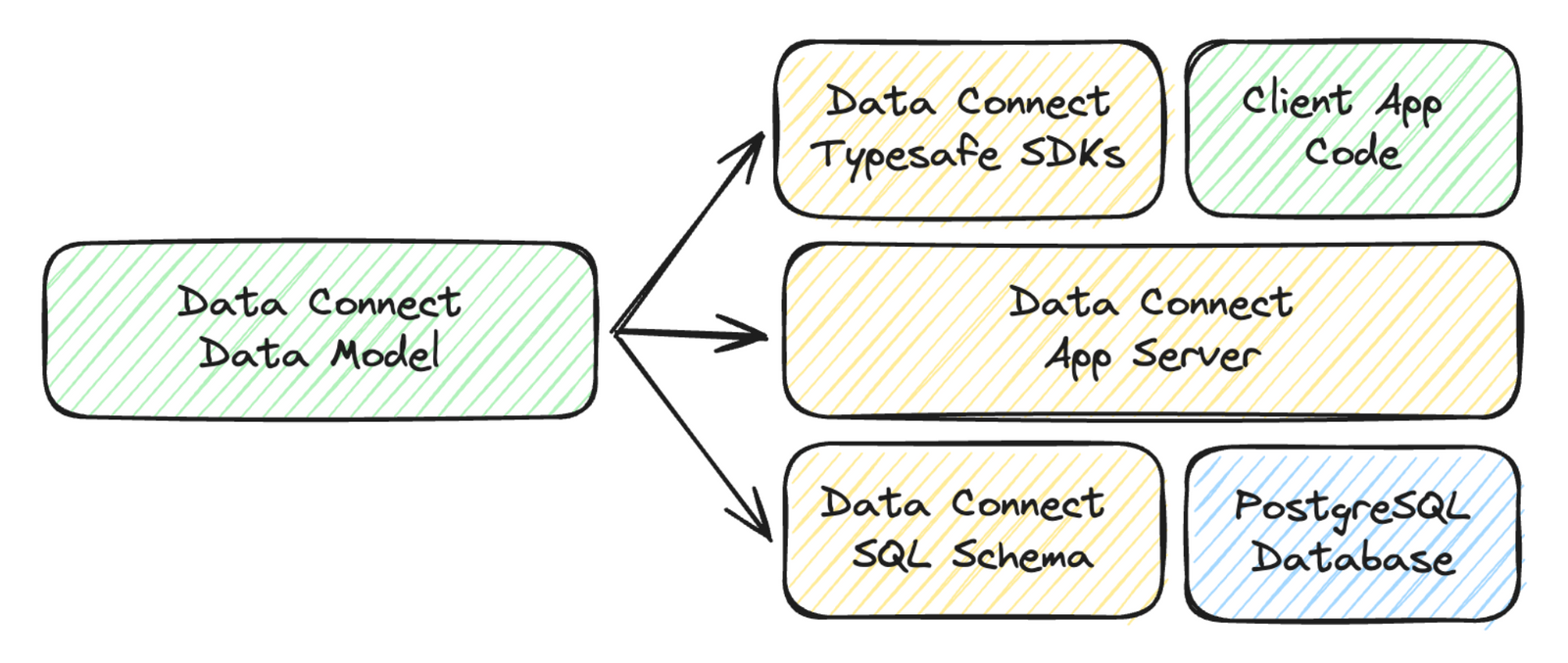
With Firebase Data Connect, you define your application’s data model, and we map it to a PostgreSQL database and generate an expressive, fully-managed GraphQL API server to query it. Your data model might look something like this:
type User @table {
id: UID!
name: String!
}
type Invoice @table {
user: User!
description: String
}
type Product @table {
name: String!
price: Int!
}
type InvoiceItem @table(key: ["invoice", "product"]) {
invoice: Invoice!
product: Product!
quantity: Int!
}
From this, we create a rich GraphQL “query builder” API for reading and writing data as well as generate the PostgreSQL DDL migration statements necessary to create a database matching your data model.
With administrative credentials, you can execute arbitrary GraphQL queries against your entire data model. For untrusted client applications, however, we took things a step further to provide a simple but “secure by default” development experience.
Let’s go back to our original code example of a “list my invoices” endpoint in an application. With Firebase Data Connect, I can express this as a GraphQL query:
query ListMyInvoices($search: String) @auth(level: USER) {
invoices(
where: {
userId: {eq_expr: "auth.uid"},
description: {contains: $search},
},
limit: 20
) {
id
createdAt
items: items_on_invoice {
quantity
product: product_on_orderItem { id, name, price }
}
}
}
From this GraphQL, Firebase Data Connect can automatically create:
- A SQL query that joins three tables together
- An API endpoint that can be called with variables and responds with the requested data
- An authentication and authorization policy for the endpoint
- Strongly-typed client code for Web, iOS, or Android platform(s)
- Tool definitions for GenAI workflows
When calling the Data Connect server as an end user of a web or mobile client, only queries that have been pre-registered as endpoints can be executed.
Query-defined infrastructure is written like Backend-as-a-Service code but can be reasoned about like trusted server code. You have full control over which operations can be performed by a client application, and each operation defines its own parameters and returned data.
In other words: you write the queries, we do the rest.
Diving deeper
QDI delivers benefits throughout all phases of an application’s lifecycle. When starting a new application, QDI provides the rapid iteration speed of a single codebase. As your application matures, Firebase Data Connect’s declarative data model provides observability, security, and maintainability benefits difficult to achieve even in a traditional 3-tier application.
We think of Firebase Data Connect as a “self-driving app server” — you tell us where to go, we generate and operate the infrastructure required to get you there. It’s a new paradigm for app development that we think shows immense potential.
In future “Query-Defined” posts we’ll explore security, API creation, SDK generation, observability benefits, and more.