
One of the major benefits of using a SQL database is that relationships between data are clearly defined and organized. Firebase Data Connect supports relationships in schemas, queries, and mutations, and this blog post will dive into setting up your schema to reflect relationships. We’ll assume that you are familiar with schemas, and you can read the Data Connect documentation if you need a refresher.
Relationships in relational databases
In relational databases, each table has a primary key to identify each record in the table, and these primary keys can be used in other tables as a foreign key to refer back to the record with that primary key. This creates a relationship between the two tables. There are one-to-one, one-to-many, and many-to-many relationships, and we’ll go over each one and how to create such relationships in Data Connect.
One-to-one relationships
In one-to-one relationships, one record in a table is associated with exactly one record in another table. For example, a “Movie” table that holds information about the movie such as title and genre can have a one-to-one relationship with a “Movie Metadata” table that keeps track of additional information such as the director, release year, and rating for each movie. A movie can have one metadata record, and each metadata is for one movie.
To define the relationship, the Movie table has a primary key that’s used in the MovieMetadata table. See this below where the Movie table with movieId as the primary key and a MovieMetadata table has movieMetadataId as its primary key. In the latter table, movieId is a foreign key, used to refer back to specific records in the Movie table.

With Data Connect, the Movie table looks like this:
type Movie @table {
id: UUID! @default(expr: "uuidV4()")
title: String!
genre: String
}You can leave the id field out, because Data Connect will automatically generate a primary key for you. The generated fields will be in implicit.gql. The code above can be simplified to:
type Movie @table {
title: String!
genre: String
}If you open implicit.gql, there will be an id field in the extended Movie class:
extend type Movie {
id: UUID! @default(expr: "uuidV4()") @fdc_generated(from: "Movie",
purpose: IMPLICIT_KEY_FIELD)
}Next, let’s see what the MovieMetadata table without the foreign key from Movie looks like:
type MovieMetadata @table {
director: String
rating: Float
releaseYear: Int
}Again, an id primary key gets automatically created and put into implicit.gql:
extend type MovieMetadata {
id: UUID! @default(expr: "uuidV4()") @fdc_generated(from: "MovieMetadata", purpose: IMPLICIT_KEY_FIELD)
}To add the foreign key with a one-to-one relationship, use @unique, which creates a field in the current table (MovieMetadata) and is a reference that holds the primary key of the referenced type:
type MovieMetadata @table {
movie: Movie! @unique
# movieId: UUID <- this is created by the above @unique
director: String
rating: Float
releaseYear: Int
}As a result, the movieId from the Movie table will be included in this table, and the movieId will match the one in the Movie table.
One-to-many relationships
In one-to-many relationships, one record in a table is associated with many records in another table. For example, let’s say there are users for our app, and each user can have one favorite movie while one movie can have many users for which it’s their favorite.

With Data Connect, the User table looks like this:
type User @table {
id: String!
username: String!
}The FavoriteMovie table has this information:
type FavoriteMovie @table(key: ["user", "movie"]) {
# User to FavoriteMovie is 1:1, as one user can have only one favorite movie
user: User! @unique
# userId: UUID <- this is created by the above @unique
# Movie to FavoriteMovie is 1:many, as one movie can be the favorite of many users.
movie: Movie! @ref
# movieId: UUID <- this is created by the above @ref
}A combination of keys becomes the record’s unique identifier, the composite key. In this case for each record, the combination of user and movie needs to be unique, hence key: ["user", "movie"].
We reuse @unique to signal that all users should be unique in this FavoriteMovie table, since each user has one favorite movie. The movie field, however, does not need to be unique because one movie can be many users’ favorite movie (a many-to-many relationship, which gets covered in the next section).
@ref for Movie is similar to @unique, in that it creates a field in the current table (FavoriteMovie) to reference the primary key of the referenced type. In this case, @ref(fields: "movieId", references: "id") is implied:
- fields: “movieId” is the name of the foreign key received from the
Movietable - references: “id” means the
movieIdfield is going to be the id from theMovietable
Writing @ref for Movie is optional, as it’s implied, so the former FavoriteMovie table’s code can be simplified to:
type FavoriteMovie @table(key: ["user", "movie"]) {
user: User! @unique
# userId: UUID <- this is created by the above @unique
movie: Movie!
# movieId: UUID <- this is created by the implied @ref
}Whenever an implicit reference is made, implicit.gql includes the type:
extend type FavoriteMovie {
userId: String! @fdc_generated(from: "FavoriteMovie.user", purpose: IMPLICIT_REF_FIELD)
movieId: UUID! @fdc_generated(from: "FavoriteMovie.movie", purpose: IMPLICIT_REF_FIELD)
}There is no id field since the combination of userId and movieId is the composite key for each record.
Many-to-many relationships
In many-to-many relationships, many records in a table are associated with many records in another table, and typically, a join table is used to store these relations. An example of this is an actor being in many movies, and a movie having many actors. The table can hold additional information like whether the actor is a main or supporting actor for a movie.
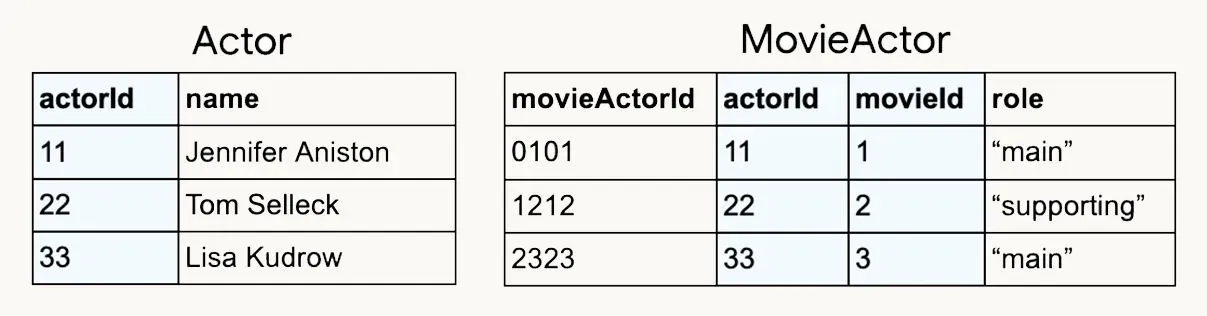
With Data Connect, the Actor table looks like this:
type Actor @table {
name: String!
}We then create a join table between Actor and MovieActors to hold the many-to-many relationships information:
type MovieActor @table(key: ["movie", "actor"]) {
movie: Movie!
# movieId: UUID! <- this is created by the implied @ref
actor: Actor!
# actorId: UUID! <- this is created by the implied @ref
role: String! # "main" or "supporting"
}Again, we declare a composite key with key: ["movie", "actor"], and there can be the same movie repeated multiple times in the table, same with actors. For each movie-actor pair, the table will say whether the actor is a main or supporting actor for that movie.
With the implied references, implicit.gql will extend the MovieActor class to include:
extend type MovieActor {
movieId: UUID! @fdc_generated(from: "MovieActor.movie", purpose: IMPLICIT_REF_FIELD)
actorId: UUID! @fdc_generated(from: "MovieActor.actor", purpose: IMPLICIT_REF_FIELD)
}Try it out!
Relationships are confusing and difficult (and not just the real-life kind), and hopefully this blog post clears up some of the muddy waters around how to create relationships in Data Connect. If you need more information about Data Connect, check out the documentation, and you can also check out other deep-dive articles. As it’s a new product, we’d love to hear your opinion and any feature requests you have as we’re hard at work improving and adding more features to the product. If you haven’t already, give Data Connect a try today - we can’t wait to see what you build with it!