
Hi, Firestore developers. We are pleased to announce that with the latest version of the client SDKs, you are able to use Firestore data bundles in your mobile and web applications! Data bundles can make certain types of Firestore applications much faster or less expensive.
That’s great! Just one tiny little follow-up question: What are data bundles?
So essentially, data bundles are serialized groups of documents — either individual documents, or a number of documents that you’ve retrieved using a specific query.
You can save these data bundles onto a CDN or your favorite object storage service, and then load them from your client applications. Once they’ve been loaded on to your client, your clients can read them in from your local cache like any other locally-cached Firestore data.

Well that just sounds like a database query with extra steps. Why would I want to do this?
The biggest reason is that by having your clients read common queries from a bundle on a CDN and then querying specifically against that cached data, you can avoid making extra calls against the Firestore database. If your application has a substantial number of users, this can lead to some cost savings, and could potentially be faster, too.
But to be clear, data bundles are an advanced feature and probably not something you should be considering until your application has a pretty sizable user base.
So what kinds of documents make sense to put into bundles?
The best kinds of bundles are ones where a majority of your users will be reading in all of the documents in that bundle, the number of documents is on the smaller side, and the contents of that data doesn’t change too frequently.
Some good examples for this might be:
- You’re storing configuration data across several documents that every client needs to read in upon startup. Since you might have millions of clients reading in the same handful of documents, this would be a great opportunity to put that data into a bundle and save a few million document reads every day.
- You have a news app, blog, or similar application, and you know that every client will be reading in the same top 10 stories every day.
- You want to load in some “starter” data for users who aren’t signed in, and you suspect the majority of your users will be ones who aren’t signed in — this is particularly useful in web applications, where you’re more likely to encounter users who aren’t signed in.
Data bundles are not good for:
- Database queries where you expect each of your users will be making different queries or want different pieces of information.
- Any data that contains private information — because data bundles are created by the server SDK, they can bypass security rules. So you need to be careful that any data bundles you load onto a client application is something that’s intended to be read by the general public.
I just had an idea: What if I were to stuff my entire database into a bundle, load that bundle onto my client, and then just query my entire database using only my cache?
That’s a terrible idea.
Remember, the Firestore cache is not particularly fast when it comes to searching through large amounts of data. Overloading your cache by asking it to store a lot of documents that your users won’t ever use is a good way of slowing your application to an unusable state. You should really only be leveraging data bundles to load up documents that most, if not all, of your users will be reading in.
Also, keep in mind that with bundles, you have to load in the entire bundle of documents when you load up a bundle, whereas with a normal document query, you’re only downloading the documents that have changed from your local cache. So from a data usage perspective, stuffing too many documents into a bundle can be quite heavy.
Gotcha. So how would I implement these?
You can read the documentation for all the details, but in general, the process will work something like this:
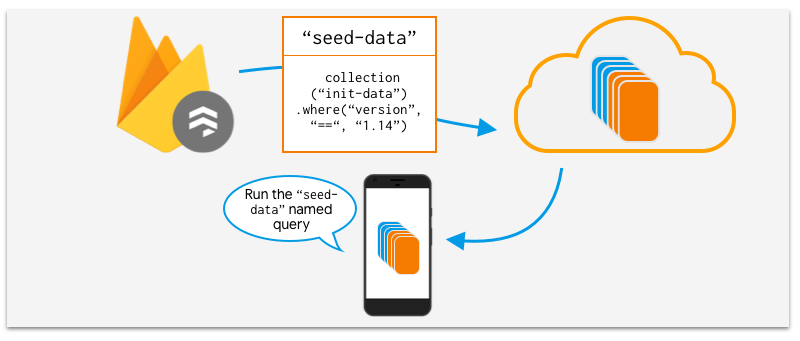
- Using the server SDKs, you would generate a bundle that consists of either individual documents, or documents generated using a query.
- You can also associate these queries with names.
- You can then store these bundles onto your favorite CDN, web hosting service, or binary storage service like Cloud Storage.
- When your client starts up, you will tell it to load in your bundle using your favorite networking library.
- Once your bundle has been properly loaded, the Firestore SDK can merge it with any cached data you might already have. This process is asynchronous, so you should wait until everything has been merged in before trying to use your bundled data.
So, once they’re loaded, I can query them like normal data?
Yes. They’ll be merged in with your locally cached data and you can make use of them like you would any other cached data. The data bundle also remembers the names of the queries you used to generate the bundle, so you can refer to these queries by name instead of re-creating them in code.
And how do I make sure I’m querying bundled data without incurring any additional Firestore costs?
The best way is to force your client to use the cached data. When you make a document request or database query, you’re able to add an option like {source: 'cache'} that directs your client to only use the cached data, even if the network is available.
Tell me more about these “named queries” — are these different from regular queries?
Not really — the trick to using bundles effectively is that you want to make sure the query you’re requesting on the client is exactly the same as the query that generated the bundle you’ve loaded. You could certainly do this in code, but by using a named query, you’re ensuring that the client will always make the same query that generated the bundle in the first place. There’s less room for error that way.
This also means that you can modify the server query that generates the bundle and, assuming you’re still using the same name, the client will also use this new query without your needing to update any of the client code.
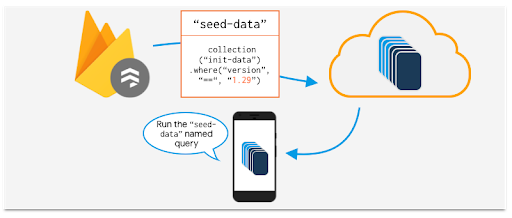
Notice that the version number has changed, but the client can continue to run the “seed-data” named query
What if I wanted to include data bundles alongside the rest of my local application data when I publish it to app stores? That way, if a user opens my app for the first time and is offline, I can read in the bundle and use that as starter data for my application.
Yes; that can be another great use of bundles. The process is the same, except you’ll be reading in the bundle using a local call. Just be aware of the warnings above — Firestore wasn’t designed to be an “offline-first” database, so try to only load in as much data as you’ll need to make sure your application is functional. If you overload your cache with too much information, you’ll slow it down too much.
Okay, I think I’m ready to start using data bundles in my application.
Great! As always, feel free to ask questions on Stack Overflow if you need help, or reach out to us on the Cloud Firestore Discussion list if you have any other suggestions. Happy coding!