


Firestore now supports Count and TTLs while removing previous scaling limitations.
Scale, speed, and ease of use are three of the most important principles of Firestore. If you issue a query to Firestore we want it to execute as quickly as possible regardless of the size of data and the incoming traffic to the database. This performant and scalable query should happen without any extra configuration on your part. It should just happen.
We are thrilled to introduce three new features to Firestore that are built on these three principles:
- Count aggregation queries.
- Improved scaling capabilities.
- Time-to-live policies (TTLs) for automatically deleting documents.
Build scalable, offline, and real-time apps all without needing a server.
Let’s dive in.
Count aggregation queries
We heard you, loud and clear. You wanted count: the count of all documents that match a query without downloading all the documents of that query.
Aggregation queries are a difficult problem to solve at scale. In the past we’ve provided solutions such as distributed counters, but they require a Cloud Function. While we have a Firebase Extension that handles distributed counters, it would be fantastic to call a function from the JavaScript SDK and get back the count.
So that’s exactly what we did. A count aggregate function is now available in Web, Android, iOS, and Node.js. Check out the web sample below with an interactive demo.
import { getFirestore, collection, getCountFromServer, query, where } from 'firebase/firestore';
const db = getFirestore();
const inventoryRef = collection(db, 'inventory');
const inventoryQuery = query(
inventoryRef,
where('price', <, 20.00),
);
const snapshot = await getCountFromServer(inventoryRef);Count works by creating a collection reference, optionally specifying a query, and then using a platform specific count function.
Collection group queries
The new count aggregation function returns the count of all matching documents of any query: including collection group queries.
The previous code snippet received the count of all documents within the /users/{uid}/shoppingCart subcollection. But what if you wanted to get the count of items in shopping carts? No problem at all. Just use a collection group query with count.
import { collectionGroup, getCountFromServer, getFirestore, query, where } from 'firebase/firestore';
const db = getFirestore();
const cartGroup = collectionGroup(db, 'shoppingCartItems');
const cartQuery = query(
cartGroup,
where('price', <, 20.00),
);
const snapshot = await getCountFromServer(cartQuery);
const totalItemsInAllCarts = snapshot.data().count;Want to restrict the query even further? No problem.
import { collectionGroup, getCountFromServer } from 'firebase/firestore';
const cartGroup = collectionGroup(db, 'shoppingCartItems');
const cartQuery = query(
cartGroup,
where('price', <, 20.00),
// Only retrieve items with a category of clothing and household
where('category', 'array-contains-any', ['clothing', 'household']),
);
const snapshot = await getCountFromServer(cartQuery);
const totalItemsInAllCarts = snapshot.data().count;Count is designed to be flexible with all query criteria in Firestore. Right now, the count function in the Firebase platform SDKs is a server only method. This means that there’s no offline or realtime support. Count is still in Preview so please give us your feedback.
Easier data structuring
Firestore’s path based design for collections and documents encourages a hierarchical data structure. Having features like count and collection group queries make it easier to structure your data with this hierarchy in mind.
It’s common for developers to question whether they should store all data in a top level collection or embrace subcollections. While every situation can be different and we have information on data structuring in Firestore, we hope that these tools make it easier for you to decide on the structure that works best for your database.
Improved scaling cababilities
Firestore has always been designed for scale since day one. We want to continue improving its capabilities to hit the level of scale needed at the most important situations.
In the past Firestore had hard limits in some areas and this required high scale apps to architect their data structures or apps defensively to handle these situations. These situations were only encountered at high scale, but that’s exactly what Firestore is for: scale.
Removing hard limits
Now Firestore has fewer scaling limits than ever.
- No maximum reads per second.
- No maximum writes per second.
- No maximum concurrent, real-time, connections
Removing these limitations makes it easier than ever to scale on Firestore.
Time-to-live policies
As you build and scale the amount of documents in your database is going to grow. Imagine you have 10,000 daily active users (DAU) and they create on average 10 documents per day. Even at 10 bytes per document, that’s 1GiB of data created a day.
When data grows it’s good to have a policy in place about how to manage unneeded documents or documents that must be deleted by compliance. Firestore now has Preview support for Time-to-live (TTL) policies that delete data after a specified time.
TTLs work a bit like an index. You indicate that a field is responsible for the timestamp that tells Firestore when to delete the document. For example:
{
"text": "This was a great meeting! All of the notes are in the recap.",
"created": "December 6, 2022 at 1:54:14 PM UTC-5",
"expiry": "January 1, 2023 at 12:00:00 AM UTC-5"
}Creating a TTL policy
The representation of the document shows that there’s an expiry field with a timestamp. To create a TTL policy for this expiry field, you can head over to the Google Cloud Console. You can find a shortcut within the Firestore data editor.
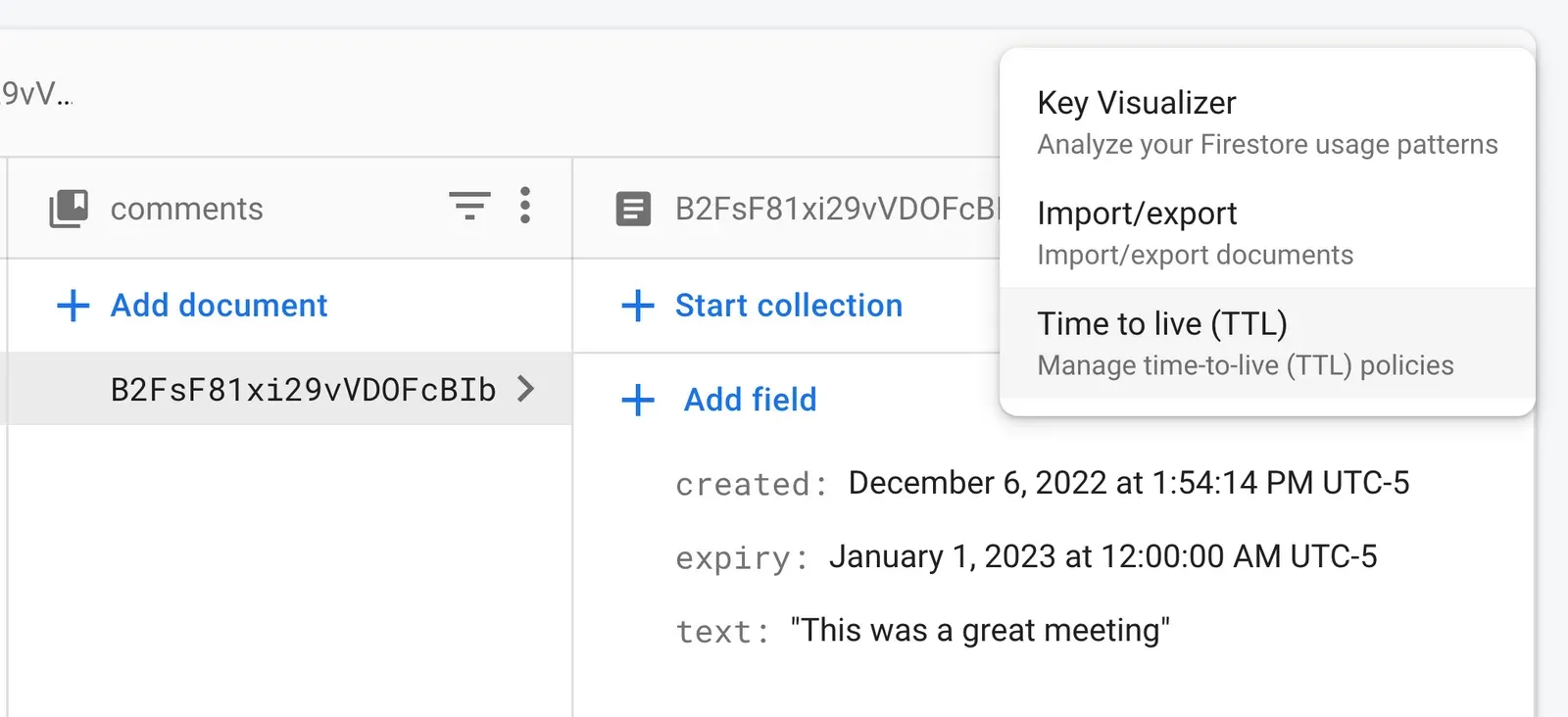
The Cloud Console asks you to specify what timestamp field serves as the TTL policy. In this case we want expiry because it’s set to delete on the new year.
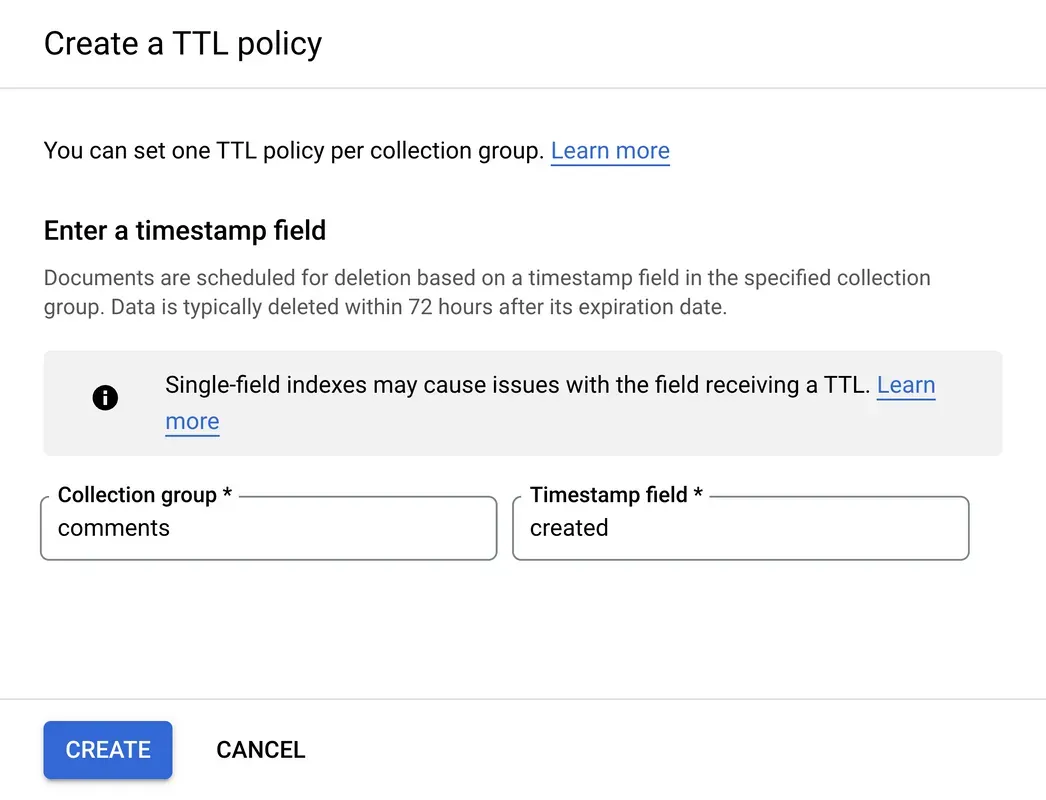
Now after the expiry timestamp Firestore will delete the document. Keep in mind that TTLs don’t delete data immediately after the timestamp. Data is typically deleted within 72 hours after the specified expiration date.
TTLs are fantastic for keeping your database up to date with relevant information. We hope that you’ll love them as much as we do.
Looking ahead
We are incredibly excited about these features and how they improve on the core principles of Firestore: speed, scale, and ease of use.
Count and TTLs are still in Preview and we look forward to your feedback and all the ways we can improve. For now if you want to give them a try, make sure you’re updated to the latest version of your platform’s Firebase SDK and check out our official documentation.
We can’t wait to see what you build.